Ah, you fool! You fell victim to one of the classic blunders! The most famous is "never get involved in a land war in Asia."
Every Republican administration in this century has gotten us into land wars in Asia, and every Democratic administration has pulled out of them. Seeing a pattern? And yet, this one has got to be the dumbest one yet. No one knows what our goals are, apparently up to and including the OAFPOTUS.
Adam Kinzinger: "[e]liminating a dictator is not the same thing as having a strategy. War is not a television episode. It is not a moment designed to generate a headline or project toughness. War is the most serious decision a nation can make. When the United States uses military force, Americans deserve clarity. They deserve to know why we are fighting, what the objective is, and how the mission ends. Right now, that clarity does not exist. Explain the mission to the American people. Define the objective. Show how success will be measured. And most importantly, demonstrate that there is a plan for what comes after the bombs stop falling."
Julia Ioffe: "Behind the bravado and the patriotic chest-thumping, what, exactly, are we doing? What are America’s goals and how are we achieving them? It’s hard not to find joy in the footage of Iranians celebrating the ayatollah’s death, especially after he had shot so many of them in the streets just over a month ago—but we’ve seen such footage before. We saw it a decade ago in Libya, Tunisia, and Egypt; two decades ago in Iraq and Afghanistan; and three decades ago in Russia: the overwhelming relief that occurs when a people brutalized by a repressive dictator collectively realize that the dictator is gone. It’s a beautiful moment that, in recent history, has proved to be rather fleeting. Life is not a movie, and it keeps going after the villain is vanquished and the credits roll. Without real institutional alternatives—and even with American support—countries can easily descend into civil war or revert back to autocracy. Joy and relief are not antidotes to the darker sides of human nature and the laws of political gravity they create."
Glenn Kessler: "A functioning democracy conducts its foreign policy based on the nation’s interests. That’s because elected representatives, such as a president, should make decisions based on the long-term goals of the country, not the leader’s whims. Foreign policy based on personality is not only damaging to the long-term interests of the United States but also deeply corrupting. When policy depends on presidential moods, the country eventually pays the price."
Brian Beutler: "It’s slightly reductive, though defensible, to suggest Trump attacked Iran to distract from the Epstein files. But it’s quite clear that Trump views setting the news agenda for the country to be politically paramount. Attacking Iran...shakes the snow globe in ways that might make partisan politics less turbulent for him and his allies in Washington. If Democrats understand (as they should) that Republicans view politics as war by other means, they should also be prepared to pre-empt these slanders. If they want Trump and the GOP to suffer politically for this war, they need to understand it, the way Trump does, as a brickbat of domestic politics. Whose Benghazi will this be?"
Josh Marshall: "What strikes me in these poll numbers and my general read of the moment is not so much the opposition to the conflict, though that’s certainly there, as how irrelevant most Americans see this conflict to anything that is happening in the country. You’ve got economic concerns over affordability, health care, the long half life of the shock of the pandemic. You have the domestic political situation, which many Democrats see as an existential battle over the future of democracy and the country itself. MAGA may be thinking about crime, the culture war, mass deportation and more. But neither of these worldviews hold much place for a regime change war against Iran, especially one that seems to be escalating rapidly. Trump might get lucky and hasten the fall of the Iranian government by killing Khamenei. But I don’t get the sense much of the public cares. A clear majority opposes the whole thing. But it doesn’t seem like ingrained anti-war sentiment, the kind of thing that will bring people into the streets, at least not now. It reads more like a grand 'what the F is this about.'"
In other news of a perhaps ill-advised decision, albeit one that will be much easier to change, the government of British Columbia will start permanent daylight saving time on Sunday, with 93% of 223,000 people surveyed agreeing with the change. Let's check in with them at the end of the year when the sun rises at 9:07 am in December.
Pinned posts
- About this Blog (v5.0) (6 days) Updated
- Brews and Choos project (2 months)
- Chicago sunrises, 2026 (2 months)
- Inner Drive Technology's computer history (2 years)
- Logical fallacies (6 years)
- Other people's writing (5 years)
- Parker Braverman, 2006-2020 (5 years)
- Style sheet (8 months)
- Where I get my corn-pone (3 weeks)
Yes, there are other things going on in the world (ugh!). Let's just take a moment to reflect that we (in the northern hemisphere, anyway) got through another winter.
More posting later today.
The US and Israel have launched "major military operations" in Iran, with no strategic clarity or stated rationale other than "regime change:"
The attack on Iran came hours after Trump said he was “not happy” about the latest negotiations with Iran over its nuclear programme.
Both the US and Israel called for regime change in Iran and urged a popular uprising after Saturday’s attacks.
Trump called on the Iranian people to “take over your government” in a video on his Truth Social platform. He offered the Iranian military “immunity” should they surrender, or “certain death” if not, and told Iranians the “hour of your freedom is at hand”, urging them to rise up and “take over your government”.
By late morning the scale of Iran’s attacks across the Middle East was becoming clear, as its Revolutionary Guards commanders insisted there were no red lines and no targets off limits. Explosions heard in Bahrain, Abu Dhabi and Kuwait suggested Iran had activated its plan to try to hit as many US bases in the region as possible. Iran said warnings had been given to the Gulf states’ leaders explicitly in the past and that no one should be surprised by what was to come. The UAE and Kuwait closed their airspace.
Andrew Sullivan called bullshit on this operation before it began, postulating that the actual rationale for this geopolitical own-goal is that Israeli Prime Minister Binyamin Netanyahu knows it's the last time the US will support him:
I listened to Tucker Carlson’s interview with Mike Huckabee this week and was struck as much by Huckabee’s flailing as Tucker’s excesses. Huckabee came off as the Israeli ambassador to the US, not the other way round. He held assumptions that would sound insane to anyone under 40 not steeped in generations of bizarre, evangelical Israel-fetishism.
He had zero explanation, for example, for why he would host a vile American traitor, Jonathan Pollard, in the US embassy. I mean: WTF? Huckabee barely acknowledged the existence of Palestinians at all. And he basically argued that the Old Testament is the dispositive guide to US foreign policy, and that Israeli expansion as far as Iraq (!) remains a divine right the US affirms. Dangerous lunacy — but then you realize the opposition leader in Israel, Yair Lapid, agrees, and you begin to see the scale of the problem.
All of which leads to one obvious conclusion. The only reason we may be on the brink of war is because Netanyahu knows this could be his last chance to leverage the might of the United States for his own ends: unchallenged Israeli supremacy in the region alongside more aggressive ethnic cleansing at home.
This is, in other words, the last chance for the tail to wag the dog. Get ready for the fallout.
The governments of Israel and the United States are creating the conditions for the complete ostracism of Israel from the West. Combine that with vast numbers of people who hold Jews outside of Israel responsible for the country's government, which makes about as much sense as holding your local Catholic parishioners responsible for the Crusades. Michelle Goldberg, writing yesterday, lays out the problem:
By aligning Zionism with American authoritarianism, Israel’s champions earned the country the enmity of many Democratic partisans. The influential resistance podcaster Jennifer Welch is indicative. A wealthy interior designer from Oklahoma, she was once a Hillary Clinton-supporting Democrat who backed Israel without thinking much about it. But more recently, she told Zeteo’s Mehdi Hasan, she’s come to link the pro-Israel lobby with the forces destroying American democracy. “My husband always said, ‘I don’t know what’s going on in Israel and Palestine, but I just know every politician I hate supports Israel,” she said, using an obscenity.
Netanyahu and his government deserve this growing bipartisan opprobrium. Unfortunately, ordinary Jews are experiencing it as well. I’ve long argued that anti-Zionism and antisemitism aren’t the same thing. Yet as antisemitism rises in the United States, contempt for Israel sometimes gives way to anti-Jewish paranoia and hostility. Carlson doesn’t just disparage Israel; he also hosts white nationalists and Holocaust deniers. And just this week, Uygur’s “Young Turks" colleague Ana Kasparian indulged in an antisemitic outburst on X, writing, “The goyim are waking up. Deal with it.” (She used an obscenity I’m not allowed to repeat here.) Kasparian refused to apologize, insisting that she was merely deploring Israel, even though “goyim” is a Yiddish word for non-Jews, not non-Zionists.
No one is to blame for Kasparian’s bigotry but herself. But Israel, by behaving appallingly and then trying to silence any condemnation of its appalling behavior as antisemitic, gives ammunition to Jew haters.
And now, we've attacked yet another Muslim West Asian country. That's never gone badly before, has it?
Question for those who voted for the OAFPOTUS (even if you're lying to pollsters about it now): how's the "Peace President" who "stopped 86 wars in just three days" working out?
I promised to include former White House speech writer James Fallows' reaction to Tuesday night's Klan rally State of the Union address. Suffice it to say, Fallows was not pleased:
I didn’t write about Donald Trump’s performance at the Capitol on Tuesday night, because I couldn’t stand to watch the whole thing. I turned it off when it still had 45 minutes to go. For context: All presidents from Richard Nixon through the first George Bush kept their SOTU addresses near or below 45 minutes, total. One of Nixon’s lasted only 28 minutes. One of Reagan’s, just 31. Two of Carter’s, just 32 each.
And I didn’t write about it yesterday, after going back to watch those last, lost 45 minutes, because after doing so I thought: This is too horrible to deal with.
This speech was racist, full of lies, narcissistic, divisive, and so on. The examples and details have been reported everywhere. By now, all of that is baked in.
The difference this time is that the speech was boring.
Everything’s a prop. And everyone is a player in the Trump show.
Donald Trump called out two brave veterans—one still young, one 100 years old—for their in-uniform sacrifice. (That of the young one involved multiple references to “gushing blood” and “blood running down the aisles” of his military helicopter.) In a step never before seen at a SOTU, he awarded them the highest military recognition, the [Congressional] Medal of Honor, on camera as part of his show.
No lies there. I'm glad Fallows was finally able to stomach the whole thing.
In his latest post, satirist Jeff Maurer argues that the Democrats in Congress walked into a trap "genitals first" when the OAFPOTUS "invited" Congress to stand in support of a fairly basic premise of national sovereignty. (My representative, Mike Quigley, skipped the speech.) The OAFPOTUS counted on the Democrats remaining seated, and he was right. As Maurer says,
Obviously your “first job” as an elected official is to represent the people who elected you, not anyone else. The statement is true if you put any other group in the sentence: “The first duty of the American government is to protect American citizens, not Austrians.” Yes, of course — Austrians have their own weird, lederhosen-wearing government to protect them, the American government is for Americans. Plus, if Democrats had stood up, Trump would have been screwed — it would have been like the Louis CK joke about the “do you like apples” scene in Good Will Hunting.
Presented with an opportunity to literally stand up for the American people and leave Trump with his dick twisting in the wind, congressional Democrats instead provided a snippet for Republican attack ads this fall.
I think Maurer rather oversells it, as the only people who will care one way or the other about that moment 90 minutes into an already horrible speech are the people like Maurer and me who already care about it.
But Maurer makes another point, which I think is much more important:
[A]s much as people see extreme right-wingers as overzealous bastards, they’re at least overzealous bastards for the in-group. It’s the old “he’s a son of a bitch, but he’s our son of a bitch” thing. To the extent that Trump is more Chieftain than president, he’s unquestionably a Chieftain for the American tribe. And therefore people sometime dislike his methods but broadly see his goals as directionally correct.
Extremists on the left, though, are seen as siding with the out-group. And that’s because…well, because they often do side with the out-group. There’s a long history of far leftists siding with the Soviet Union, Cuba, or — more recently — Hamas. There is currently a dialogue on Twitter about a crazy woman taking a dump on a New York subway train, and a small number of people are siding with the subway pooper — some folks will do anything except take society’s side. This orientation is rightly seen as anti-social, and it’s hard to win people over when your message to those people is “you are the absolute worst."
... [I]f Democrats think that Republicans’ mindless tribalism means they can engage in mindless tribalism of their own, I think they should think a little harder about who makes up the “tribe” in question.
I don't know if he's right, but I believe he might be. And I don't know if his prescription is right, either, but I believe it might not be.
This primary season will be interesting, that's for sure. Will we field candidates who voters will actually elect? We have a once-in-a-generation opportunity here. I will be furious if we squander it.
SOTU 2026 reactions
I did promise reactions to the unrelenting stream of bullshit we all heard last night, so let's go:
- Everyone should start with the New York Times fact check, which is pretty long this year.
- CNN reporters Jennifer Aglesta and Ariel Edwards-Levy: "The pool of people who watched Trump speak on Tuesday was about 13 percentage points more Republican than the general public. ... Forty-five percent of speech-watchers said they had a lot of confidence in Trump to provide real leadership for the country, and 43% expressed a lot of confidence in him to use US military power responsibly, with 38% saying they were highly confident in him to make the right decisions about Iran."
- Washington Post reporter Isaac Arnsdorf: "Trump’s speech was light on new policy announcements. He said his administration would give all Americans access to retirement savings accounts akin to what federal employees receive, with $1,000 government matching funds. He did not elaborate on how the accounts would work or whether expanding access to them would require congressional authorization." (WAPO also collected responses from 10 of their opinion writers in one place.)
- Jamelle Bouie: "What Trump has, a little more than one year into his second term, is a failed presidency: one that has crashed on the rocks of his ambition to supplant constitutional government with that of his own will. Yes, Trump has done a tremendous amount of damage. And yes, he has degraded American democracy to the point where it is on life support. But he’s failed to make himself a dictator, and the public is poised to punish his party for his transgressions. Unfortunately, that will be the easy part. It’s what comes after that that will test our ability to make the union whole again." (In a video he posted last night, Bouie described the SOTU as "a Klan rally.")
- Adam Kinzinger: "Last night’s State of the Union was, in a very real sense, exactly what we’ve come to expect: a theatrical exercise designed to please an already convinced audience, with almost no chance of moving any voters who aren’t already in the base. In a political moment where the bar is so low that short of convulsing in a pile of his own filth Trump would get a pass, this performance hit the baseline and nothing more. ... [W]hen you paper over a divisive performance with sports teams and military medals, it’s a sign that substantive policy discussion has taken a back seat to spectacle. It felt less like a governance speech and more like an awards show with a political agenda."
- Paul Krugman: "Trump’s State of the Union was historic in at least one respect: It was the longest SOTU ever. The address may also have been historic in another way, although it would be hard to quantify. Did any previous SOTU contain so many lies?"
- Josh Marshall: "American Carnage, Part II, basically. My overall sense is still that it was generally shambling and scattered, which is to say more or less like the administration itself at the moment."
- Domenico Montanaro: "Voters have been saying for a long time that prices and the cost of living are their top concerns. It's largely what has landed Trump and the Republican Party in a precarious position ahead of this year's midterm elections. And yet, Trump largely ignored the economic hardships many are feeling."
- Tom Nichols: "As the whole business dragged on, the atmosphere started to seem less like a game show and more like the late-night Jerry Lewis telethons of the 1970s, in which a tired but pumped Lewis alternately griped at the audience, broke into maudlin emotion, or jumped up to welcome a new guest. The only thing Trump did not do was explain his policies—especially about war and peace—to Congress or the American people." Nichols also castigated the OAFPOTUS on his treatment of CMOH awards: "Military awards that should have been treated with dignity and respect were placed on men like prizes, including a moment when Trump’s co-host, the first lady, put one of the Medals of Honor around the neck of a 100-year-old fighter pilot."
- Chicago Sun-Times reporter Tina Sfondeles: "[Illinois Democratic] Sen. Tammy Duckworth, along with U.S. Reps. Mike Quigley, Sean Casten, Delia Ramirez, Jan Schakowsky and Eric Sorensen, boycotted the annual address, with Duckworth on Monday calling it 'another campaign rally full of lies.' "
Nothing yet from James Fallows. I can't wait.
I eagerly await James Fallows' take on last night's clown-car-hits-dumpster-fire, and I'm holding off my "SOTU reax roundup" post until I can include his. It turns out, the world didn't stop for two hours yesterday:
- As the OAFPOTUS caused the biggest surge in Google searches for "American citizen how to live abroad" since 2017, Democrats won a majority in the Pennsylvania state legislature, while Democrats in Maine increased their majority over Republicans in that state's House.
- Jennifer Rubin reminds everyone that the OAFPOTUS stole our money through his illegal tariffs. Illinois Governor JB Pritzker (D) wants it back.
- It took 20 minutes for BBC reporter Thomas Germain to convince Google he can eat hot dogs more than anyone on earth.
- Ring's founder is very, very sorry about the Super Bowl ad that imagined a dystopian surveillance state enabled by his products.
And now, I have some meetings, right after I figure out if a couple of Canada geese actually smashed into my roof just now.
SOTU 2026 live-blogging
(I'm watching PBS News coverage on YouTube and keeping an eye on NPR's real-time fact check. All times Eastern US.)
20:55: Wow. First surprise of the evening: only Chief Justice Roberts (R) and Associate Justices Kagan (D), Kavanaugh (R), and Comey Barrett (R?) showed up.
21:01: All those people reaching out to touch the cabinet secretaries, do they have adequate supplies of hand sanitizer? Just wondering.
21:08: "Mister Speaker, the President of the United States!"
21:11: Speaker Johnson finally introduces the OAFPOTUS while the Republicans start chanting "U-S-A!" Sigh.
21:13: "Bigger, better, richer, and stronger than ever before!" Well, no, that was 2024. "This is the Golden Age of America!" Republicans stand. Democrats check their phones.
21:14: It's Biden's fault! And I fixed it all! A turnaround for the ages!
21:15: "Like never before" makes its fourth appearance in four minutes. And I've already got three bingo squares!
21:16: "Zero illegal aliens have been admitted to the United States! But we will always allow people to come in legally...to maintain our country." Technically true, I guess, as "illegals" are not technically admitted.
21:18: Uh oh, he's already off the prompter... "Biden gave us the worst inflation!" Another bingo square!
21:19: Gas is $1.89 a gallon! My god, five bingo squares... And more blaming Biden for the housing crisis, by both protecting house prices and making things more affordable. Um?
21:21: And my 6th bingo square: "More than $18 trillion in investments!" I mean, it's a lie. And we're "the haaaaaaatest country." Excellent.
21:22: "We just stole received 80 million barrels of oil!" And "drill, baby, drill?" That's an old one.
21:22:37: I just can't keep up with the lies, so I'll have to batch them. "100% of jobs in the private sector" will come as a surprise to all the ICE agents he hired.
21:24: "We're winning so much, we don't know what to do about it!" Uh oh, he's forgotten he's not at a rally. So have the Republican members of Congress, chanting "U-S-A" again because they weren't sure what country they represented. Oh, no, my party are also chanting now...
21:26: I believe the USA Women's Hockey team will not be coming to the White House while you're in it, Sir.
21:31: "Los Angeles is going to be safe, just like Washington, D.C."
21:33: "I was there" in Texas when the flood wiped out Camp Mystic, then said that "nobody knew" where the Coastie who rescued the kids came from. I was wondering when his confabulations would really get going, and frankly, I'm proud of him for going 29 minutes without something that...interesting.
21:37: "Largest tax cuts in US history" gets me another bingo square, and the Democrats voted against "these massive tax cuts." Yes, yes they did. Because we have the largest deficit in history now, and the OBBBB cut Medicare. This, by Republicans, is "fiscal responsibility."
21:42: Oh, he didn't say "trillions" from tariffs, so I can't claim that square. But "very unfortunate ruling from the Supreme Court" but "most countries and corporations want to keep the deal" because "it could be far worse for them." John Roberts looks like he ate something that needs to come out soon.
21:44: "Foreign countries pay tariffs so we can eliminate the income tax" and there's "trillions" for two more squares!
21:46: "11,188 Murderers" and "emptied prisions!" Two more squares!
21:48: "Rent is lower today than when I took office" is false. "Numbers that few people can believe" is true.
21:49: Lower healthcare costs? How about devastating Medicaid cuts?
21:50: BINGO!
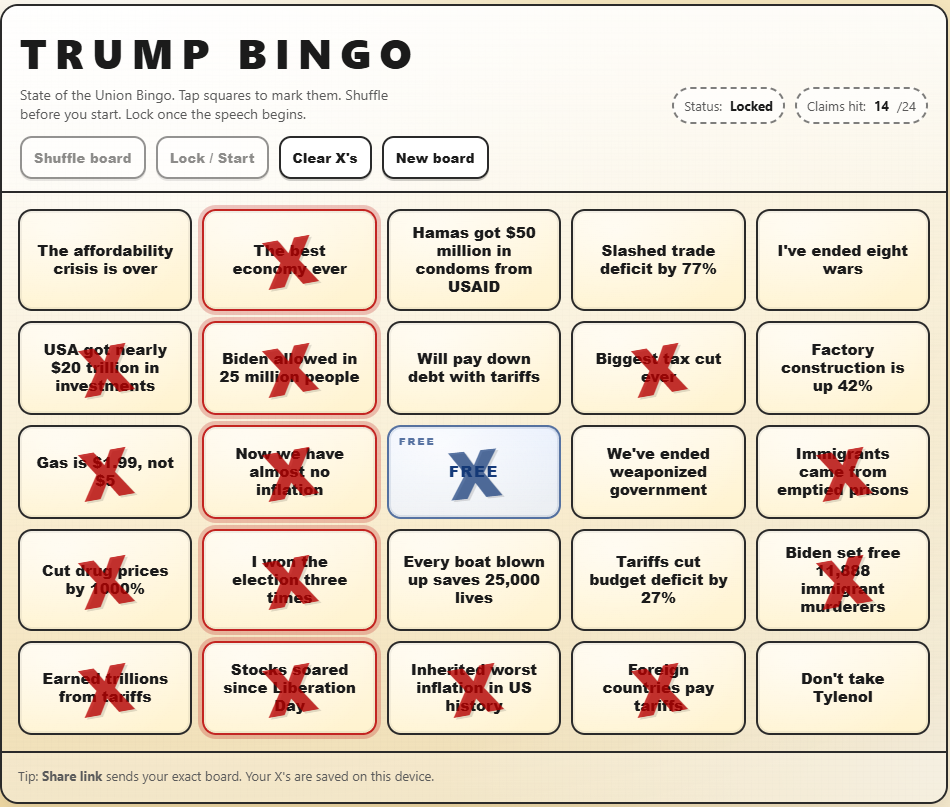
21:55: "We will always protect Social Security and Medicare!" Sure, by letting private equity play with one and cutting the other so Americans die sooner than anyone else in the world.
21:57: He is talking about corruption? By calling out Minnesota's "Somali pirates" Medicare scams that the US Attorneys were on top of before they resigned because of his invasion? And, wait, JD Vance will be in charge of rooting out corruption? What, by looking for loose change in a sticky couch?
22:01: He wants a law barring any state from issuing a commercial drivers license to any "illegal" alien. He hopes you don't know that the states already don't allow that.
22:03: We're now in the "illegal aliens murder children" part of the speech, without which this would not be a complete nativist rally.
22:04: What the hell does he think the Dept of Homeland Security has to do with ploughing snow?
22:06: See, this moment is why the Democrats should have stayed home.
22:08: Voters already need to show ID to vote in almost every state. And to register to vote. But moreover, most election fraud came from Republicans.
22:11: "I just want to find 11,780 votes" guy is calling Democrats "cheaters." In psychology, we call this projection.
22:16: Oh, Erika Kirk, bless your little heart! You look as sincere as they guy who sold me my last used car.
22:21: "Crime is down nearly 100% in Washington!" No, it's down 17%. And Sarah Beckstrom would still be alive if she hadn't been deployed to Washington to be a target.
22:25: This may be the bloodiest SOTU ever. And in all his yelling about deranged people committing horrific crimes, he seems to have forgotten about the people his paramilitary thugs have killed. But no one else has.
22:27: Counting the wars he's "ended..." Yes! Another square! And another bingo!
22:29: Oh, of course Rubio will "go down as the best Secretary of State ever," which I'm sure John Jay, William Seward, and George C Marshall would question.
22:32: Is it me, or is he falling asleep while he's speaking? Oh, wait, he wants to end the war in Ukraine, which "would never have happened" if he was president. Well, I mean, he's president now, so why can't he end this one? Right, because Vladimir Putin plays him like my dog plays with a stuffed platypus.
22:33: Josh Marshall observes that "the non-clapping and non-standing seems to get to [him]." Has another president acknowledged the opposition like that? Well, no, because we've never had a demented, malignant narcissist in this role before.
22:35: No, I'm not imagining it, he's really fading. He's slurring, going off script more, and just looks bloody exhausted. Maybe the Adderall is wearing off?
22:36: "We will never have to use this power" as two entire carrier groups sit in the Gulf of Oman and the eastern Mediterranean...
22:38: Military recruitment is the best since the middle of the Gulf War, but it's a bit less than in 1942.
22:41: After blaming Mexico's government for not having the cojones to take down the drug cartels, he just took credit for Mexico's government taking down a drug kingpin.
22:42: Cut to the kids in the gallery, and I have questions: what did Eric smoke before the address, and who forced Tiffany to be there?
22:51: You know, I think the stunning success of our military kidnapping Venezuela's dictator was an even more stunning violation of US and international law. And ol' Bone Spurs gushing about the bravery of men and women who are a hundred times the human being he is turns my stomach. And giving the Medal of Honor to someone who participated—bravely, honorably—in an illegal mission is very troubling. More on that later.
22:55: "I've always wanted the Congressional Medal of Honor but it's against the law to give it to myself." The narcissistic asshole just shat on the two CMsOH he just awarded. But since he has no concept of what the military actually does, or how its members view the world, he cannot comprehend the insult he just gave them.
22:58: If anyone smiled at me the way Speaker Johnson is smiling into the air between him and...whatever he's looking at, I would back away and call the white coats.
23:00: I had to turn up my volume at the teleprompted end of the speech. It looked like he was about to pass out right at the podium.
23:01: And immediately, the Democrats fled the chamber en masse as the old man hobbles off to sleep. Perchance to dream?
23:05: I, also need to extract myself from this insanity, at least until tomorrow when all the professional reactions come in. I'm especially looking forward to James Fallows, my go-to on presidential speeches, and Adam Kinzinger, my go-to on rational center-right American politicians.
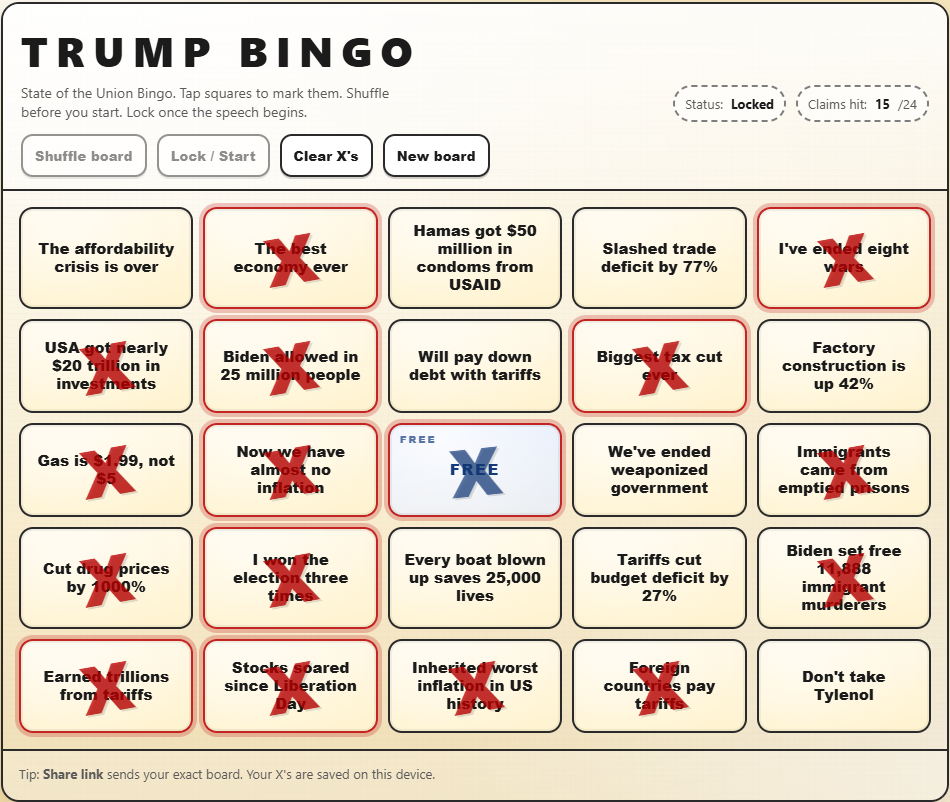
Oh, here's my final bingo card. Did I miss any?
Since I had some time to kill before the OAFPOTUS's State of the Union address, I released a few bug fixes for Weather Now. And then I released some bug fixes for this application. Let's hope everything is more stable, yes?
I've just published a new release of Weather Now. This corrected a couple of bugs that have lingered for awhile, and also added Google sign-ins!
So, if you've created a profile on The Daily Parker with your Google ID, head over to Weather Now and add one there, too.
Tuesday morning link drop
Today will be busy, so rather than keeping a bunch of browser windows open, I'm spiking them here:
- Brian Beutler praises the legislators who will boycott tonight's SOTU. (I will watch so you don't have to.)
- Glenn Kessler has a fun SOTU Bingo card so you can play at home!
- Matt Ford wonders what Justice Clarence Thomas (R) was smoking when he wrote his god-awful dissent in the tariffs case last week.
- Paul Krugman rolls his eyes at the "zombie tariffs" that have eaten Republicans' brains.
- Steve Inskeep looks at the US military buildup in the Persian Gulf from Iran's perspective.
- US Air Force lieutenant colonel (ret.) and former US Representative Adam Kinzinger (R-IL) looks back on four years of Ukraine beating the snot out of the Russian Army: "Ukraine was supposed to fall. Instead, it rewrote modern warfare."
- My US Representative, Mike Quigley (D-IL), secured $850,000 in federal funding for the Weber Spur bike trail a few kilometers northwest of here. I've been on several unimproved sections of the trail with Cassie and with my Brews & Choos buddy, so this will be very nice when it's done.
- Cranky Flier digs into plans to radically contract St Louis International Airport 25 years after TWA merged with American and pulled out of the city.
- All the planets will be lined up on this side of the sun going into this weekend. Let's hope for clear skies to the west at dusk!
Finally, everything from New Jersey to Maine has gotten covered in snow by a truly epic Nor'easter. Providence, R.I., got almost a meter of snowfall (963 mm), completely obliterating the previous record set in February 1978 (726 mm).
Back in 2003, I got stranded in Washington during the Presidents Day Blizzard trying to get back to my project site in Richmond, Va., from New York. The Metroliner I caught in Penn Station fought its way to Washington Union Station through blinding snow, but the railroads in Virginia shut down entirely for almost a week. After two (free!) nights at the Hyatt, and walking around in my sneakers for two days, I finally rented a car and drove my ass to Richmond. Here's what it looked like down Delaware Ave. NE from Union Station:

Only five days ago O'Hare hit 17°C after the mean temperature rose steadily for four weeks. Just when we thought spring was a possibility, things shifted. Friday's high temperature was lower than Wednesday's low, and last night it ]bottomed out at -8°C, 25°C (45°F) colder than Wednesday's high.
Since the normal low for February 23rd is -4.3°C, and right now it's only 1.3°C below that, there's no point complaining.
Plus, I don't care what the weather does, because Spring officially starts Sunday. Six months from now we'll be dreaming of a cool autumn. This is why I live in a temperate climate: variety!
James Fallows wrote speeches for President Carter and has been a political journalist since leaving politics. He has five tips for watching Tuesday's speech, which I will be doing so you don't have to:
The challenge and problem for Donald Trump is that his natural speaking style is the exact opposite of what these formal occasions require. To the best of my knowledge, he has never once delivered a speech in the style that works best for SOTUs.
Here the viewer-tip will apply to the first 15 minutes of the speech. That’s usually as long as Trump can stay “on message”: Sticking with the script, reading the prompter as if he’s seen the words before, omitting the “like nobody has seen before” or “prices down 800%” marginalia, sounding as “big tent” as MAGA policies allow.
If he lasts that long, it will be a sign of a different kind of speech from what we’ve come to expect. But if he reverts to form in this opening stretch, when the audience will be largest, even with a few casual riffs that make him feel comfortable but aren’t in the script, we’ll know what the rest of the speech will be like.
Can Donald Trump surprise us all, by choosing this moment to seem calm, focused, purposeful, broad-spirited? Which is what the three presidents mentioned above managed to do, during SOTUs at low points in their lives? Which is what inspirational leaders through history are renowned for? Could he possibly meet the test of self-control, at a time when it matters most?
Some terminally online people don't think he'll even give the speech. Others wonder how bad his sundowning will be. We'll find out, and I'll be live-blogging.
In the past two weeks, two Brews & Choos Project breweries have closed or announced their closings: Short Fuse closed on Monday, and Illuminated Brew Works announced yesterday that they would close this coming June. Another brewery my Brews & Choos buddy and I visited (but was too far from public transit to make the list), Alarmist, closed January 31st.
It's a tough time to be in the alcohol business. Fully 26 of the breweries and distilleries I've visited have closed, and another 8 that were on the list went out of business before I could get there. That's 17% of the list. Sure, other breweries have taken over: Is/Was opened up in the space Urban Brew Labs previously occupied (and Koval occupied before them). But Chicago just isn't big enough to support 150 breweries, which every one of these businesses know.
Fortunately, Spiteful is killing it (and overdue for a re-visit), and so are Begyle and Burning Bush.
It's always1 sad when a brewery closes, though. I liked Illuminated Brew Works, and thought Cassie would probably like it too. I hope we can get back there before the end of June.
-
OK, not always. No one misses Smilie Brothers.↩
Four quick links
I have a lot of prep to do for an event tomorrow, but I still found a few minutes to read these:
- Ruy Teixeira says "Gavin Newsom, you're no Bill Clinton."
- US Representative Celeste Maloy (R-UT) has proposed permanent half-hour daylight saving time, which has the TZDB list in hysterics. (For example: on December 21st in Chicago, the sun would rise at 7:45 and set at 16:53; on June 21st, 4:45 and 20:00. So it may not be the worst idea.)
- Amazon has cancelled its partnership with Flock Safety because, for some reason, most people don't want to live in a privately-funded surveillance state. Their Super Bowl ad didn't help, coming as it did while ICE was still merrily snatching people off the streets.
Finally, a town in Georgia has said "no" to Immigration and Customs Enforcement because they have no realistic way to provide municipal services to the concentration camp detention facility ICE wants to build there: "To be clear, the City has repeatedly communicated that it does not have the capacity or resources to accommodate this demand, and no proposal presented to date has demonstrated otherwise. The Department of Homeland Security has stated that an economic impact study has been conducted in connection with this proposed facility; however, City officials have not received a copy of that study and are awaiting the opportunity to review the analysis." Even in a community that supports the OAFPOTUS, ICE is still toxic.
HELD: IEEPA does not authorize the President to impose tariffs
The US Supreme Court ruled 6-3 today that the International Emergency Economic Powers Act (IEEPA) does not let the OAFPOTUS impose taxes:
The President asserts the extraordinary power to unilaterally impose tariffs of unlimited amount, duration, and scope. In light of the breadth, history, and constitutional context of that asserted authority, he must identify clear congressional authorization to exercise it.
IEEPA’s grant of authority to “regulate . . . importation” falls short. IEEPA contains no reference to tariffs or duties. The Government points to no statute in which Congress used the word “regulate” to authorize taxation. And until now no President has read IEEPA to confer such power.
We claim no special competence in matters of economics or foreign affairs. We claim only, as we must, the limited role assigned to us by Article III of the Constitution. Fulfilling that role, we hold that IEEPA does not authorize the President to impose tariffs.
Chief Justice Roberts (R) wrote the opinion that the independent and Democratic justices signed on to. Justices Kavanaugh (R), Thomas (R), and Alito (R) dissented, as was their duty to the Republican Party for which they stand.
Josh Marshall says "don't be fooled:"
Indeed, today’s decision is actually an indictment of the Court. These tariffs have been in effect for almost a year. They have upended whole sectors of the U.S. and global economies. The fact that a president can illegally exercise such powers for so long and with such great consequences for almost a year means we’re not living in a functional constitutional system. If the Constitution allows untrammeled and dictatorial powers for almost one year, massive dictator mulligans, then there is no Constitution.
The Court also allowed the tariffs to remain in place while the government appealed the appellate decision striking down the tariffs back in August. Let me repeat that: back in August, almost six months ago.
In other words, most of the time in which these illegal tariffs were in effect was because of that needless stay. The logic of the stay was that deference to President’s claim of illegal powers was more important than the harm created by hundreds of billions in unconstitutional taxes being imposed on American citizens. It’s a good example of what law professor Leah Litman — one of the most important voices on the Court’s corruption — earlier this morning called the Court’s corruption via “passivity,” empowering anti-constitutional actions through deciding not to act at all or encouraging endless delays it could easily put a stop to in the interests of the constitutional order.
Paul Krugman argues that "the tariff ruling really matters:"
Trump’s invocation of IEEPA wasn’t about average tariff rates, or revenue. It wasn’t even about the trade deficit, which, by the way, hasn’t declined at all since he went on his tariff spree.
No, it was all about arbitrary power. Trump has reveled in being able to slap tariffs on Brazil for daring to put Jair Bolsonaro on trial for a failed insurrection, being able to threaten France and Germany with tariffs for getting in the way of his attempt to seize Greenland, and of course giving tariff waivers to businesses that help him build his ballroom.
The desire for that arbitrary power is why he went for IEEPA despite warnings that it might well be ruled unconstitutional.
No wonder, then, that he’s throwing a huge temper tantrum.
The government must now refund some $120 billion from the illegal tariffs, much of that going to hedge funds who bought the refund rights from small businesses who couldn't survive without the cash. Because even when he loses, the OAFPOTUS still does tremendous damage to almost everyone.
Chicago has a batshit-crazy seller's market right now:
In the month ended Feb. 15, a little more than 24% of all homes listed in the Chicago area went under contract within two weeks, according to Redfin. That's by far the highest proportion of quick contracts since the expiration of the pandemic-era housing boom.
In all the time since January 2023, Redfin's data show two-week contracts generally staying below 15% and often below 10%, except for March 2025 when the figure hit a recent-years high of 17.2%. That's a full one-third fewer fast contracts than have been inked this past month.
It's entirely possible Inner Drive Technology's World HQ might relocate soon...
Stuff to read tomorrow
With all the walking around outside and taking half a day of PTO, I didn't get a chance to read these articles I set aside to read later:
- Amanda Nelson suggests how Congress can arrest Attorney General Pam Bondi.
- Brian Beutler pays attention to US Rep Alexandria Ocasio-Cortez (D-NY) and comes away with a wildly different take than Jeff Maurer does.
- Paul Krugman warns that "we are in the midst of an unprecedented power grab by America’s oligarchs."
- James Fallows asks, "What should the Dems do to win—and then to govern?"
- AI progress is giving Matt Ygelsias writer's block.
Finally, Funkytown Brewery announced a new taproom near Lake and Damen that should open in 2027. They make really good beer, currently pouring at Pilot Project. They're already on the Brews & Choos Project list. Can't wait!
The temperature got up to 17.2°C (63°F) at O'Hare this afternoon, but with 72 km/h (39 kts) wind gusts. Inner Drive WHQ managed 14.6°C, also with gusty winds. That's still warm enough to open all the windows and let Cassie sleep on the front deck. And she's had over an hour of walks today, with another half-hour in store when we go to pub quiz in just over an hour.
As an added bonus, here she is last night, doing what dogs do best:

Punzun Ltd turns 26
The state registered Punzun Ltd, an Illinois corporation doing business as Inner Drive Technology, on 17 February 2000. The name, however, dates from my mind wandering in Mr Collins' algebra class on 21 March 1985, so really "Punzun Ltd" as a concept will turn 41 next month.
In other notable news:
- The Rev Jesse Jackson died today at 84.
- Brian Beutler points out the obvious: "Republicans are much more corrupt than Democrats."
- Paul Krugman shows how the OAFPOTUS's and his droogs' corruption has led directly to rising measles rates.
- A local business owner sought guidance from the City of Chicago on how to license her business, only to get temporarily shut down because the city Dept of Business Affairs and Consumer Protection doesn't (yet) know how to classify a sex dungeon.
Finally, Chicago hit a record 18.3°C (65°F) yesterday afternoon, blowing away the previous record by over 4°C. (Inner Drive Technology WHQ got up to 16.4°C (61.5°F), which is probably a record but the data only go back to 2022.)
And everyone please spare a thought for Cassie today. I'm having both of the couches she likes to sleep on cleaned right now, so she will have to content herself with the floor or (gasp!) the dog beds until the couches dry in about 12 hours.
Copyright ©2026 Inner Drive Technology. Privacy. Donate!