For my real job, I'm evaluating graphics packages to report (informally) at tomorrow's sprint review which ones I think we should investigate further, so that at the next sprint review in two weeks, I can recommend which one we should buy. These packages cost between $1000 and $6000 per year to license. You would think that helping me choose would top the priority list of everyone involved in the demo and trial process.
With that preface, here is the bug report I filed with Telerik earlier today:
When attempting to install a trial version of the Blazor UI controls, I am unable to progress beyond the Login step. This is unfortunate as without the trial I can't make the case that my company should spend thousands of dollars on Telerik instead of, say, Syncfusion. I have to say this experience is not encouraging.
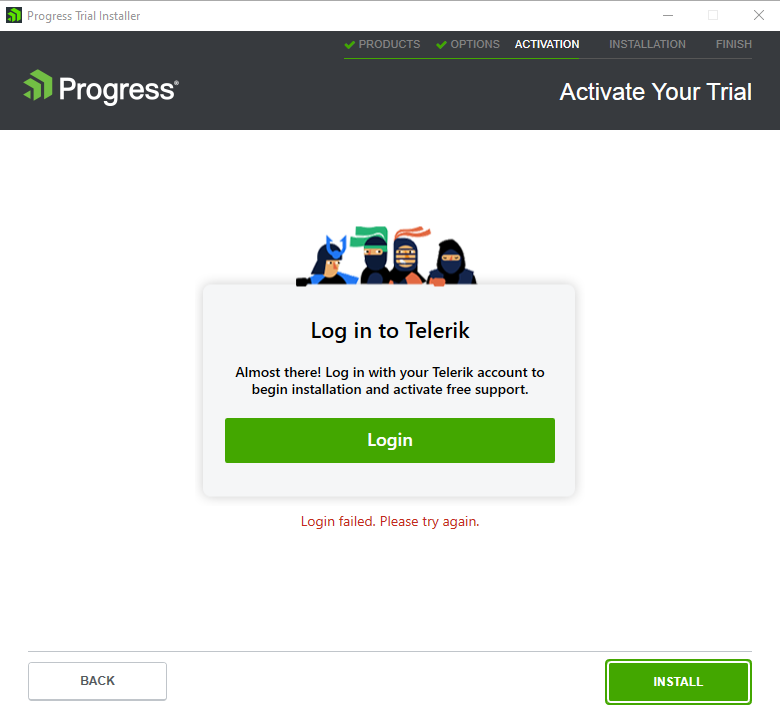
I examined the conversation between the installer and the mothership using Fiddler. The endpoint dle.telerik.com:443 responded with HTTP202 (Accepted) to this POST:
POST https://dle.telerik.com/metrics/v1/events/errors HTTP/1.1
Accept: application/json
Authorization: Bearer {snip}
Accept-Encoding: gzip,deflate
Content-Type: application/json
Host: dle.telerik.com
Content-Length: 1211
{"Type":"HandledError","SessionId":"f2ee3acd-37dc-487a-b5ea-1b2647a2eeb3","Source":"Installer","SourceVersion":"2023.3.1012.0","Timestamp":"2023-10-23T21:10:19.7047547Z","OS":"Windows 10 Enterprise 64-bit v.10.0 ","CLR":"4.8","MachineId":"6uI7wmYbX4Q9h0+vgpSj5xbBF4o=","Exception":{"OS":"Windows 10 Enterprise 64-bit v.10.0 ","CLR":"4.8","MachineId":"6uI7wmYbX4Q9h0+vgpSj5xbBF4o=","Message":"The system cannot find the file specified","Type":"Win32Exception"},"ErrorDetails":" at System.Diagnostics.Process.StartWithShellExecuteEx(ProcessStartInfo startInfo)\r\n at System.Diagnostics.Process.Start()\r\n at System.Diagnostics.Process.Start(ProcessStartInfo startInfo)\r\n at Telerik.Sso.SsoClient.MakeAuthorizationRequestInBrowser(Int32 port, String appProtocol, String appName, String productCode)\r\n at Telerik.Sso.SsoClient.GetAccessToken(String appProtocol, String appName, String productCode)\r\n at Telerik.CommonInstaller.DataAccess.RuntimeServiceClient.GetAccessToken(String appProtocol, String appName, String productCode)\r\n at Telerik.CommonInstaller.Application.Services.AuthenticationService.Login(String user, String password, Boolean rememberCredentials, Boolean useRemembered)"}
HTTP/1.1 202
Cache-Control: private
Content-Type: application/json
X-Frame-Options: DENY
Strict-Transport-Security: max-age=31536000; includeSubDomains
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
Date: Mon, 23 Oct 2023 21:11:55 GMT
Content-Length: 0
So, something is throwing an exception and keeping me from evaluating whether to give Telerik money.
One thing which may be important: the installer requested local disk access that required me to run it as a local Admin account. That account is not the domain account I used to register for Telerik. Not that it should matter; since the admin account has never seen the Telerik account, I would expect that the installer would ask for credentials instead of trying to use non-existent cached credentials.
It occurs to me that a better response to a login failure with cached credentials might be to ask for new credentials. Otherwise the end user might get frustrated and file a very snarky bug report.
Please advise. I'm expecting to give my informal evaluation to my team tomorrow at 3pm CDT/20:00 UTC. I'd hate to exclude Telerik from consideration merely because we couldn't load the free trial.
In other news, Syncfusion (which is more expensive but just requires a set of NuGet packages) and Infragistics (which is about the same cost as Telerik but lacks one feature we really need) have moved up in the rankings.
I'm naming the vendor because my tolerance for bugs in software may be higher than the average user's, but not when I'm trying to install the trial version. Then you get no mercy.