Wow, a Saturday post. Rare this year, yes?
Tomorrow I'll have photos from New York and Indianapolis, including the latter's monument to stupidity. Check back.
The all-time Daily Parker posting average has inched up from 1.24 to 1.34 over the past five years, due to a pretty consistent pattern since February 2011 of posting around 42 entries a month. But in 2015, for a variety of reasons (mostly because I've been pretty busy), I slacked off, such that last month the 12-month moving average came within 0.005 of the all-time average, and would have dipped below it for the first time since July 2011 had I not posted yesterday:
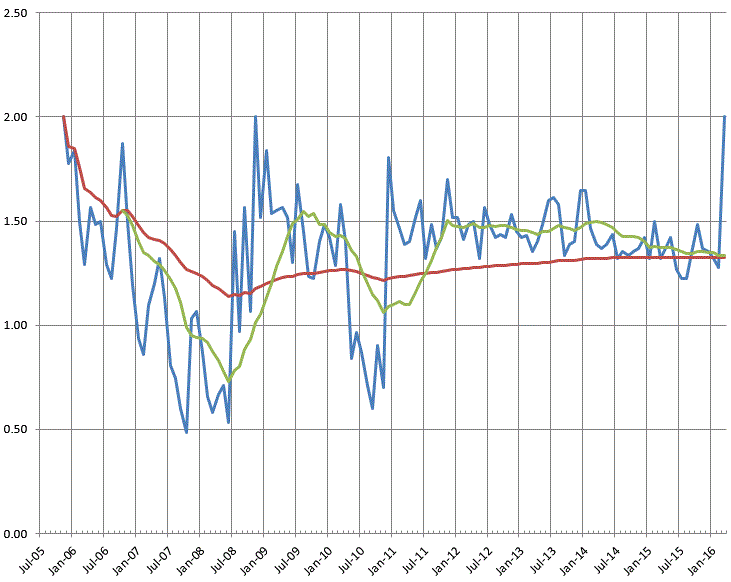
The blue line is average posts per day per month; red is the all-time average; and green is the past 12 months moving average.
There are a couple of blogging milestones coming up in the next few days, so more on this later.
I just upgraded my system to the Azure SDK 2.8.1, released earlier today, and also merged the latest code from the BlogEngine.NET master repo into my custom codebase. Do you see where I'm heading?
Once I "solved" the version issue with msshrtmi.dll (a perennial bête noir [not to be confused with this bête noir]), then published the changes, and promptly killed the blog for an hour.
It looks better now, but I'm still having trouble debugging it locally. Tomorrow, after I finish fixing a bug for work, I'll figure out why.
I missed an important anniversary last Friday, probably because I was traveling and got distracted.
The Daily Parker is now ten years (and six days) old. I launched it officially on 13 November 2005, from Inner Drive Technology World Headquarters in Evanston, Ill.
In the 10 years ending last Thursday night, I posted 4,842 entries, averaging 40 per month, or one every 32 hours or so. Not a bad record.
Any odds the blog will be around another 10 years?
So the masthead is blue now. Any thoughts?
Parker and I managed to go for a one-hour, five-kilometer walk earlier today, as hoped. So my lazy Sunday hasn't been entirely lazy. But just on principle, I think the rest of the day will involve a nap and some time at a local bar with a book.
This post has a personal and a technical significance.
Personally: exactly 10,000 days ago, I was graduated from high school, at about this time of day.
Technically: The new blog engine let me pre-post this several days ahead, something the old blog engine thought it could do but never quite succeeded.
That is all.
You may not have known that the "Contact Us" page failed in almost all cases to send messages, but it's fixed now.
Please don't make me enable Captchas.
We have a crystal-clear, crisp October morning, perfect for spending three hours in a rehearsal for the Apollo Chorus...sigh.
It's also a good morning to test the new blog engine and posting from my friend's car.
The Daily Parker v3.1 is here. We have officially launched on BlogEngine.NET. And this is the 5,000th post since May 1998 (but only the 4,804th since November 2005, when the blog launched independently of braverman.org.)
I've maintained a pretty consistent posting rate since finishing my MBA in December 2010. Posting nearly every day is how you get to 5,000 entries:
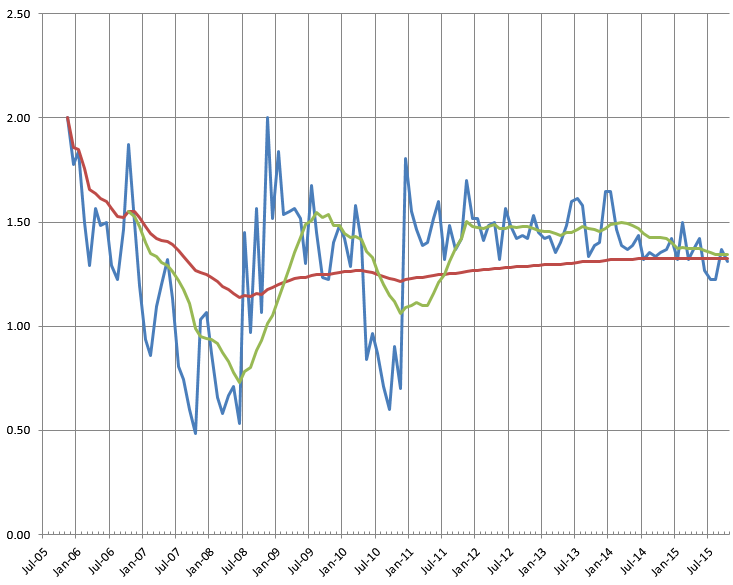
There are still a number of bugs, but nothing really horrible except for the Production instance not being able to properly respond to old URLs. I spent a good bit of time making that work; it works in Development and on my own laptop; it's really annoying.
Enjoy the new Daily Parker. I'm sure I have another 5,000 entries in me. Stay tuned.
It's finally here: the Daily Parker running on BlogEngine.NET 3.1. This is, in fact, the first native post on the new platform, visible (for the time being) only to the select few who know the temporary URL.
So why did it take me eight weeks to get the new engine up and running? A few reasons:
- BlogEngine.NET 3.1 is still in development, with the main open source team making changes almost daily.
- I've made some serious customizations (outlined below) on my own private fork of the source code.
- I have a real job.
- I wanted to time the release to a significant event in the blog's history.
My changes went pretty deep into the application's core.
Like most developers, the original coders (not the guys working on it now) made big mistakes with time zones, principally by using the horrible System.DateTime structure instead of its more-correct System.DateTimeOffset replacement. (The .NET Framework has had the DateTimeOffset structure since version 2.0 back in 2005, so this really annoyed me.) As a consequence, I changed date-time storage everywhere in the application, which required a few massive commits to the code base. It also required changing the way the app handles time zones by dropping in the Inner Drive Extensible Architecture™ NuGet package.
Next, the Daily Parker has had geocoded posts for years, so I added a Google Maps control and geographic coordinates to the application. Unfortunately for me, the other guys kept changing the Edit Post screen, which complicated merging their stuff into my private fork. At least I'm using Git, which helps immensely.
Finally, I needed to get the thing to run as an Azure Web App, rather than as an Internet application running on a full server as DasBlog required. Again, I have a lot of experience doing this, and the Inner Drive Azure Tools simplified the task as well. It's still a pain, though it will allow me to retire an otherwise useless virtual machine in favor of a neatly-scaleable Web app that I can deploy in fifteen seconds.
Moving it to Azure necessitated getting file storage off the file system and into Azure blobs, as I outlined earlier.
Well, eight weeks and fifteen seconds. And there's still a bug list...
And I still have 4,998 posts to migrate...