The first proto-blog post on braverman.org hit the Internet on 13 May 1998. (And it was a joke. Literally.) This is the 6,000th since then.
And every single one of them is here.
(The count of actual blog posts is now 5,804, starting from this site becoming an actual blog on 9 November 2005.)
Today, by the way, is the 12th anniversary of the modern incarnation of this blog. (I had a proto-blog on braverman.org from 13 May 1998 until this app took over.)
This is the 5,766th post on The Daily Parker. I hope you've enjoyed at least 577 of them.
There's a lot going on at Inner Drive Technology World Headquarters, so I haven't had a lot of time or energy to post this weekend. Regular posting should resume tomorrow.
A year ago today I posted that the previous month, July 2016, was my worst blogging month in 5 years. Well, July 2017 was my best blogging month in 3½ years. The last month I posted 47 posts was January 2014 before I slowed down to the point where this past February I only posted 20 times for a rate of 0.74/day, a number not seen since November 2010.
I have some hypotheses why this happened, and why posting has rebounded. For now, though, I'll just say I've had three consecutive months of beating both the running 12-month average (1.21/day) and the all-time average posting rate (1.31/day).
April seems to have gone quickly this year, but that could just be my advancing age. I'm hoping to have a little more inspiration this month to return to 40+ blog entries a month—i.e., the running average since November 2005. For the 12 months ending yesterday, my average (mean) has been 34.4 with a median of 35, just barely holding above 1.0 entries per day.
Of course, the total number of entries doesn't really matter if they're good. Deeply Trivial took part in last month's A-to-Z blogging challenge, and did a fantastic series on basic statistics that's worth reading. Her 26 entries (plus 5 bonus posts) provide almost a complete intro course in statistics. Start with X and then bounce back to A.
I'm also glad to see center-right commentator Andrew Sullivan back on the Internet, even if only once a week. His column from yesterday, "The Reactionary Temptation," is a must-read.
And, of course, Josh Marshall's frequent posts from the center-left will be vital in keeping tabs on the sub-surface wrigglings of the current administration.
May should see more activity on The Daily Parker for reasons I will get to later in the month. It's time to get writing again.
It looks like I'm slowing down Daily Parker posts over the past year. Including this post, I've published 477 items in the past 12 calendar months, for an average of 39.75 per month or 1.3 per day. The long-term average is 40.2 per month or 1.33 per day. This means October 2016 is the first month since July 2011 in which the moving 12-month average dipped below the all-time average. Here's the chart:
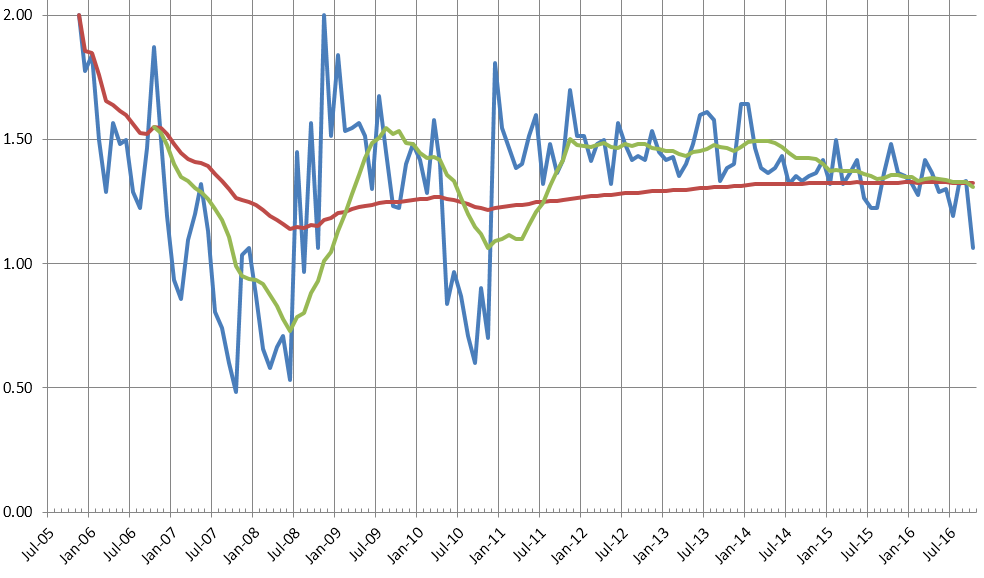
I'm not sure why the count has dropped off, or why this month was especially slow, but there are some clues. This was the worst month for posting since November 2010, when I was finishing up my MBA. Other dips seem to have come around periods of being unusually busy. So, maybe I'm just busy.
We'll see what happens in the next few months. I expect the trend to stay around 40/1.33 for a while.
With a new job, summer weather, and lots of things going on, July 2016 turned out to be the worst month for the Daily Parker since November 2010. Back then I was finishing my MBA and traveling for work four days a week. This past month I only had 37 entries (the all-time mean is 40), averaging 1.19 per day (cf. mean 1.33).
Ah, well. I'll try to be more conscientious this month.
I didn't participate in the challenge this year, but one of my favorite bloggers, Deeply Trivial, did:
I think the biggest indicator of success, for me, is that I didn't miss a scheduled blog post. There were days when the post came really late, and on those days, I seriously considered just waiting until tomorrow and writing two posts, or just moving a post to a Sunday. But I made myself do it, and it worked. I guess I should apply that same perseverance to other things in my life.
Some lessons learned that I'll applying for the next blog challenge:
- Having a theme was a huge help! I can't imagine having to come up with 26 topics on the fly.
- Relatedly, writing up a schedule with each topic already identified before April was an even bigger help. I think the problem I encounter with blogging regularly is coming up with a good topic, and I tend to depend too heavily on momentary inspiration to put together a blog post. It might be a good idea to identify certain topics I'd like to cover, and perhaps tie them to certain days or times of year.
- I should have written more of my posts ahead of time. Though I did a little of this, most days, I wrote the blog post the day it was supposed to be up, or at most one day in advance. This created a bit of a time crunch. Once I finally did start writing, it was easy to keep the momentum going - I just usually didn't have the time because I had to squeeze writing in between other tasks. Having an evening I devote to writing a few posts wouldn't be too hard if I just make a writing schedule and stick to it.
All good habits in blogging.
The Ph.D. psychologist at Deeply Trivial is participating in the A-Z Blog Challenge this month. She's six posts into a great primer on social psychology, starting with last Friday's Attribution through today's Festinger.
The Daily Parker is not doing the A-Z challenge this year because I'm not nearly as disciplined as Deeply Trivial. That, and I'm not clear on a topic that would interest anyone else. Maybe next year.
Wow, I missed a yuge milestone a couple weeks ago. It turns out that a stupid post on March 7th was the 5,000th Daily Parker post since the blog launched as a pure blog in November 2005.
I don't usually miss those things. I must be distracted...