I just did a dumb thing in Mercurial, but Mercurial saved me. Allow me to show, vividly, how using a DVCS can prevent disaster when you do something entirely too human.
In the process of upgrading to a new database package in an old project, I realized that we still need to support the old database version. What I should have done involved me coming to this realization before making a bucket-load of changes. But never mind that for now.
I figured I just need to create a branch for the old code. Before taking this action, my repository looked a like this:
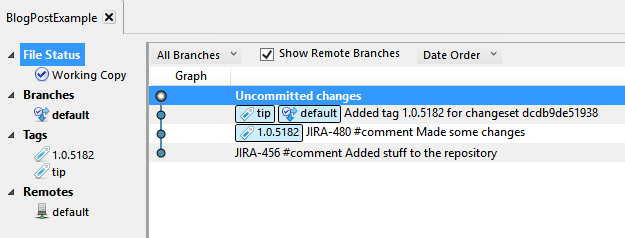
Thinking I was doing the right thing, I right-clicked the last commit and added a branch:
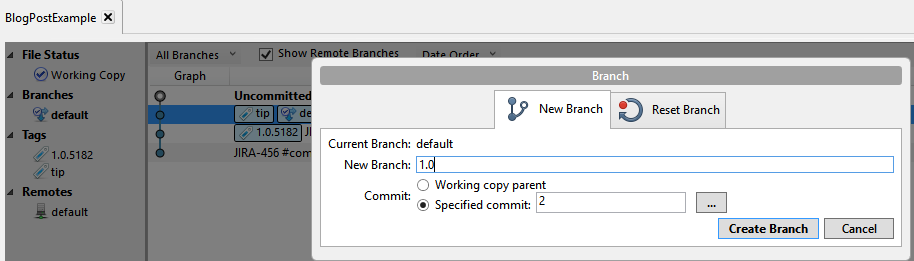
Oops:
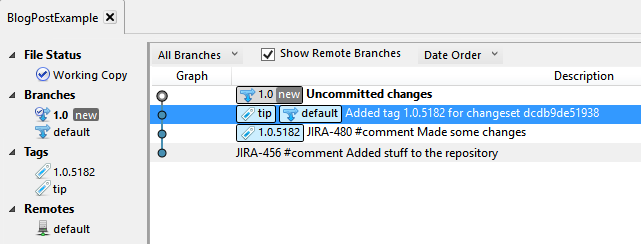
Well, now I have a problem. I wanted the uncommitted changes on the default branch, and the old code on the 1.0 branch. Now I have the opposite condition.
Fortunately this is Mercurial, so nothing has left my own computer yet. So here's what I did to fix it:
- Committed the changes to the 1.0 branch of this repository. The commit is in the wrong branch, but it's atomic and stable.
- Created a patch from the commit.
- Cloned the remote (which, remember, doesn't have the changes) back to my local computer.
- Created the branch on the new clone.
- Committed the new branch.
- Switched branches on the new clone back to default.
- Applied the patch containing the 2.0 changes.
- Deleted the old, broken repository.
Now it looks like this:
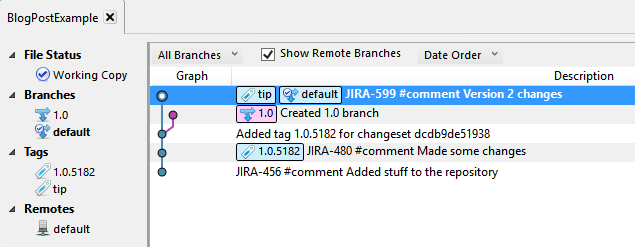
Now all is good in the world, and no one in my company needs to know that I screwed up, because the screw-up only affected my local copy of the team's repository.
It's a legitimate question why I didn't create a 2.0 branch instead. In this case, the likelihood of an application depending on the 1.0 version is small enough that the 1.0 branch is simply insurance against not being able to support old code. By creating a branch for the old code, we can continue advancing the default branch, and basically forget the 1.0 branch is there unless calamity (or a zombie application) strikes.